
Ich war in Schottland im Urlaub und habe mich sofort in die Landschaft verliebt. Auf meinen zahlreichen Reisen durch Deutschland habe ich das Gefühl bekommen, dass es hier und im restlichen Europa auch ähnliche Landschaften geben müsste.
Wo außer in Schottland findet man noch schottische Highlands? Gibt es diesen Typ Landschaft ein zweites Mal in Europa? Vielleicht sogar in Deutschland? Dieses Projekt ist von der Neugier getrieben – ich wollte aus den reinen Höhendaten Erkenntnisse über die Ähnlichkeit von Regionen zueinander gewinnen.
Es geht darum herauszufinden, wo sich Gebiete in Europa beim Darüberwandern „gleich“ anfühlen. Wie groß sind die Hügel oder Berge um mich herum, wie weit sind sie weg, gibt es viele kleine oder wenige große Höhenunterschiede? Oder gar keine? Das Ergebnis soll eine Karte sein, auf der Gebiete, die diese Ähnlichkeiten aufweisen, gleich eingefärbt sind.
Man kann sich das so vorstellen, wie wenn man unterschiedliche Textilien in die Hand nimmt. Man kann sie sofort erkennen und vielleicht sogar gruppieren, einfach nur nach dem Gefühl, das sie beim Berühren auslösen.
Wie Cluster gefunden werden
In diesem Beitrag wird der Begriff „Clustering“ ziemlich häufig verwendet.
Clustering beschreibt das Zusammenfassen ähnlicher Datenpunkte zu Gruppen. Im konkreten Fall werden Geografische Regionen anhand mehrerer Merkmale in eine von zehn Gruppen eingeteilt. Man kann sich das Clustering bildlich vorstellen, wenn man Personen in Gruppen gleicher Körpergröße einteilen möchte. Dann ist es natürlich nur ein Messwert, der berücksichtigt wird.

Der Fingerabdruck einer Landschaft
Das Ziel des Projekts ist das Clustering (also das Gruppieren) von Landstrichen in zusammengehörige Gruppen. Ergebnis: Auf der Karte sind Gebiete gleich eingefärbt, die eine ähnliche Topographie haben.
Es funktioniert ganz ähnlich wie ein Audio-Analyzer; den hat jeder schon mal in irgendeiner Form gesehen. Die zugrunde liegende Analyse nennt man „Fast Fourier-Transformation“ (FFT).
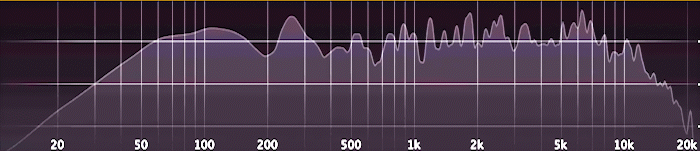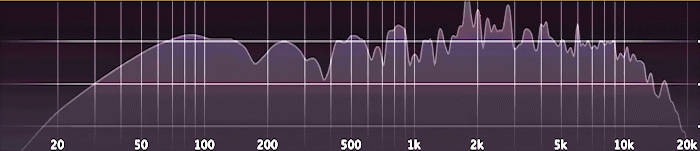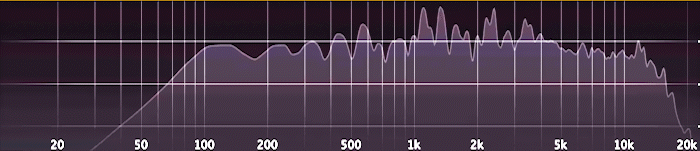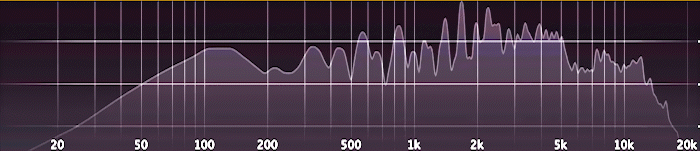
Doch statt auf Schallwellen wendet man diese Analyse jetzt eben auf die Höhendaten einer Landschaft an. Vereinfacht gesagt ergeben sich aus der FFT-Analyse dann für jedes Stück der Landschaft mehrere Messwerte (in diesem Fall siebzehn). Diese spezifische Kombination von Werten entspricht dem „Fingerabdruck“ dieses Gebiets. Der erste Messwert gibt an, wie stark sich weit auseinanderliegende, breite Hügel erheben. Der letzte Messwert misst feinkörnige Unebenheiten in der Landschaft.
Es hilft nicht, einfach zu messen, wie hoch oder niedrig die Landschaft ist, sonst würde man einfach nur nach Höhenlage clustern. Um einen „Fingerabdruck“ einer Landschaft zu erstellen, nutzt man deshalb die angesprochene Frequenz-Analyse.
Ergebnisse visualisiert
Ich habe hier stellvertretend für die verschiedenen Landschaftstypen 3D-Visualisierungen erstellt. Es sind Bereiche von ca. 15 x 15 km und die Landschaften sind an ganz unterschiedlichen Orten in Europa.
Über den Bildern kann man jeweils den „Fingerabdruck“ der Landschaft sehen – und zwar den der angrenzenden Landflächen – Wasser wird ignoriert. Wie dieser „Fingerabdruck“ entsteht, wird gleich erklärt.
Cluster 1/10

von Padua,
Italien

von Kiel,
Deutschland

von Peterborough,
Vereinigtes Königreich
Cluster 2/10

von Rostock,
Deutschland

von Peterborough,
Vereinigtes Königreich

von Nantes,
Frankreich
Cluster 3/10

von York,
Vereinigtes Königreich

von Magdeburg,
Deutschland

von Stettin (Szczecin),
Polen
Cluster 4/10

von Lille,
Frankreich

von Warrington,
Vereinigtes Königreich

von Mansfield,
Vereinigtes Königreich
Cluster 5/10

von Verona,
Italien

von Northampton,
Vereinigtes Königreich

von Montpellier,
Frankreich
Cluster 6/10

von Turin,
Italien

von Dublin,
Irland

von Cork,
Irland
Cluster 7/10

von Logroño,
Spanien

von Le Havre,
Frankreich

von Cork,
Irland
Cluster 8/10

von Vitoria-Gasteiz,
Spanien

von Cork,
Irland

von Genua,
Italien
Cluster 9/10

von Florenz,
Italien

von Genua,
Italien

von Telford,
Vereinigtes Königreich
Cluster 10/10

von Toulouse,
Frankreich

von Livorno,
Italien

von Brescia,
Italien
Von den Höhendaten zur fertigen Karte
Um jetzt z.B. ganz Europa zu bearbeiten, braucht man folgende Schritte: Zunächst die Höhendaten. Die kann man sich wie ein Schwarzweiß-Satellitenbild vorstellen, bei dem Berge weiß und die Meeresebene schwarz sind – die Helligkeit entspricht hier der Höhe. Diese Höhendaten stammen aus dem EU-DEM-Dataset des Copernicus-Programms der Europäischen Kommission und werden direkt über die API der OpenTopography-Plattform bezogen.


Als Nächstes teilt man diese Höhendaten in Kacheln gleicher Kantenlänge auf und dehnt sie noch gerade (azimutal-äquidistante Projektion). Die quadratischen Kacheln haben 12 km Seitenlänge. Sie dürfen nicht zu klein sein, weil sonst die Rechendauer extrem steigt – sie dürfen aber auch nicht zu groß sein, weil sonst die Karte zu grob wird und man somit vielleicht Details bestimmter Landstriche verpassen würde. 12 km ist ein gutes Mittelmaß.


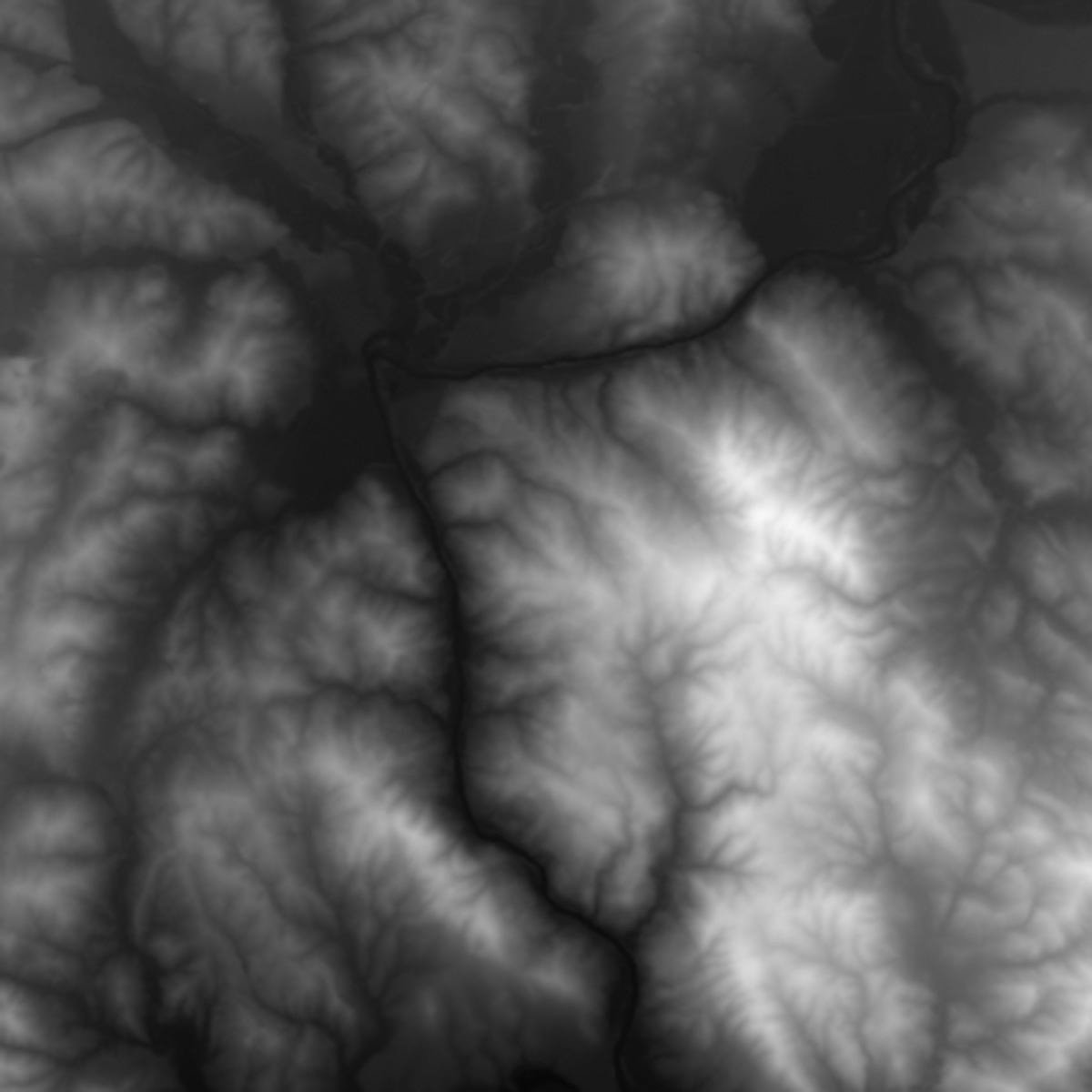
Für jede Kachel folgt dann die FFT-Analyse und die Summierung der 17 verschiedenen Frequenzbereiche. Diese 17 Werte, hier als Balken dargestellt, sind der „Fingerabdruck“ einer Kachel.
Jetzt kann man alle Kacheln nach der Ähnlichkeit ihrer Fingerabdrücke gruppieren. Für jede Kachel ergibt sich also eine Zugehörigkeit zu einer von zehn Gruppen. Die geografische Lage der Kachel ist für die Gruppe egal – so kann es dann eben sein, dass dieselbe Gruppe in Schottland, den französischen Cevennen und im Schwarzwald existiert.
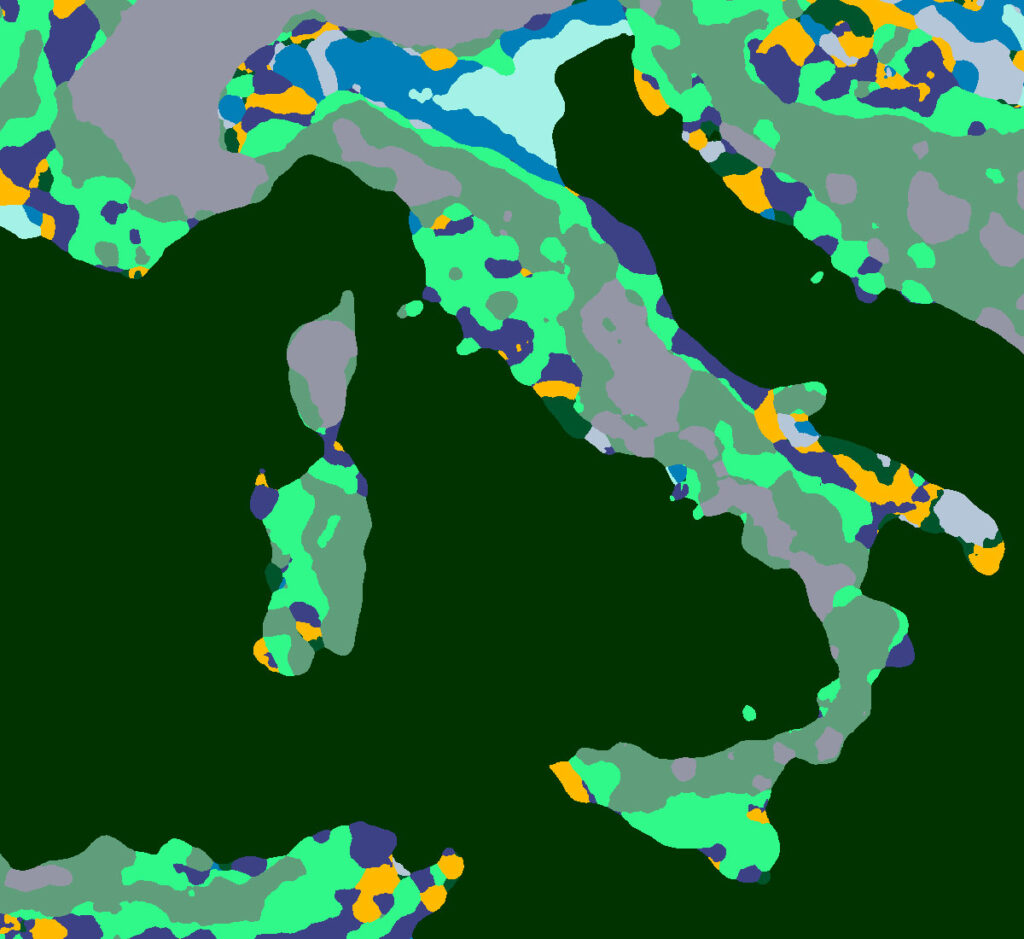
Wenn die „Fingerabdrücke“ jeder Kachel geclustert sind, und man jeder Gruppe eine eigene Farbe zuweist, dann ergibt sich folgendes Bild. Hier kann man die Verteilung der verschiedenen Landschaftstypen schon ganz gut abschätzen.

Die Karte ist aber noch ziemlich faserig und feingliedrig. Damit man leichter einschätzen kann, welcher der zehn Landschaftstypen in welchem Gebiet vorkommt, wird die sich ergebende Karte so gefiltert, dass sie darstellt, welcher Landschaftstyp in der näheren Umgebung am häufigsten vorkommt. Dadurch fallen unnötige Details raus, die bei einer qualitativen Einschätzung eher hindern als helfen.
Grenzen bei der Entwicklung
Dieses Projekt ist ein exploratives Projekt – ich habe ja schon verschiedene Hyperparameter angesprochen, wie die Kachelgröße, die Anzahl der FFT-Stufen, die Anzahl der verschiedenen Landschaftstypen. An all diesen und noch mehr Stellschrauben lässt sich drehen – was die Ergebnisse verändert. Durch Experimentieren und meine subjektive Einschätzung bin ich auf die Werte gekommen, die letztlich hier verwendet wurden. Sie liefern ein visuell schönes und subjektiv nachvollziehbares Ergebnis.
Point of Failure
Ich stand in dem Projekt häufig davor, es hinzuschmeißen. Rückblickend waren einfach so viele Konzepte in Python noch komplett neu für mich, außerdem fehlte mir die Erfahrung mit den Geodaten. Als ich dann aber die ersten visuellen Ergebnisse gesehen habe, war ich echt froh, es nicht abgebrochen zu haben. Nach und nach sind mir dann aber die Schwächen aufgefallen, bis zu einem Punkt, an dem ich schon wieder aufgeben wollte. Was ist denn überhaupt die „perfekte“ Karte für diesen Zweck? Gibt es einen Messwert, einen Qualitätsindex? Woher weiß ich, dass ich am Ziel bin mit dem Projekt? Ist es nicht ein bisschen schwach, einfach nur ein „schönes“ Ergebnis zu haben?
Ich habe viel darüber nachgedacht – und nein. Ein schönes Ergebnis ist gut. Ein nachvollziehbares Ergebnis ist im Rahmen einer explorativen Datenanalyse (EDA) komplett richtig.
Was dabei herausgekommen ist
Das Programm spuckt die Ergebnis-Karte(n) als GeoTIFFs aus. Das ist letztlich einfach ein Bildformat, bei dem noch die geografische Projektion und Position hinterlegt ist. Ich wollte es möglichst nutzerfreundlich haben, und daher kann man die fertigen Kartendaten direkt in Google Earth oder QGIS öffnen. Dorrt lassen sich die Cluster auf den 3D-Erddaten betrachten. Das ist für die Exploration super wichtig, weil man gleich (subjektiv) prüfen kann, ob die gleichen Cluster wirklich auch in verschiedenen Ländern gleiche Landstriche erfassen.
Damit man das Ganze aber auch hier im Browser nutzen kann, habe ich noch eine Software entwickelt, die aus den ganzen Ergebnissen eine Karte generiert, die man hier ansehen kann. Die GeoTIFFs sind einfach viel zu groß und ohne spezielle Software für den Leser sonst nicht nutzbar.
In der Karte sind die „repräsentativen Beispiele“ der jeweiligen Cluster mit Kreisen markiert. Das sind die Orte, die oben als 3D-Kacheln dargestellt sind.
Mich hat am meisten überrascht, dass es in Deutschland (östlich vom Rheingraben) tatsächlich Landschaften gibt, die – nach den eng gesteckten Kriterien dieser Analyse – denen der schottischen Highlands ähneln. Außerdem fand ich es schlüssig, dass das Gebiet um München herum in drei der landschaftlich „langweiligeren“ Cluster fällt – es entspricht meiner Erfahrung, dass man gut 25 Kilometer in jede Richtung reisen muss, bevor die Landschaft überhaupt einmal sanfte Hügel bekommt.
Außerdem fiel (subjektiv) auf, dass besonders oft Nationalparks und Naturschutzgebiete länderunabhängig in ähnliche Cluster fallen. Das könnte man noch untersuchen, es scheint hier eine Korrelation zu existieren. Meine Vermutung dazu ist, dass Ländereien, die schwer zugänglich und schwer zu bebauen sind, sich häufiger und leichter zu Schutzzonen erklären lassen – und diese fallen dann eben in gleiche oder ähnliche Cluster. Das wirft eine interessante Frage auf: Kann man mithilfe der Karten, die sich aus dem Projekt ergeben, vielleicht weitere schützenswertere Gebiete identifizieren?
Proof of Concept



Letztlich konnte mir dieses Projekt meine Frage also beantworten. Ja, es gibt Landschaften in Europa, und sogar in Deutschland, die von der Form her denen Schottlands ähneln. Auf der interaktiven Karte (etwas weiter oben) kann man sich selbst orientieren und schauen, wo die Landschaften sich(topografisch) ähneln.
Diskussion
Einflussreiche Parameter und Subjektivität
Es gibt viele Stellschrauben in dem Projekt, die das Ergebnis beeinflussen. Das sind:
- Die Kachelgröße und wie stark sie sich überlappen
- Die Anzahl der Frequenzbereiche und ihre Verteilung
- Die Anzahl der Cluster
- Wie stark die Ergebnisse geglättet werden
Die Ergebnisse sind deterministisch, das heißt, sie sind nicht vom Zufall beeinflusst, können wiederholt werden und basieren immer direkt auf den zugrundeliegenden Daten. Die Stellschrauben verändern also nicht, wie ähnlich sich die Landschaften sind, sondern die Darstellung und die Qualität der Karte. Außerdem lässt sich beeinflussen, dass z.B. näherliegende Unterschiede in der Landschaft größeres Gewicht haben. Also wie hügelig es auf den nächsten 300 Metern ist, spielt für die Klassifizierung eine stärkere Rolle, als wie stark sich die Landschaft z.B. über Entfernungen von 15 km verändert.
Das ist der Subjektivität der Analyse geschuldet. Die Parameter wurden so eingestellt, dass ich sagen konnte: Ja, diese zusammenhängenden Landstriche sind in sich kohärent, sie gehören wirklich zum selben Cluster. Und ja, diese Landstriche sind denen desselben Clusters in einem anderen Land auch ähnlich.
Wie schon angesprochen ist das für eine explorative geografische Analyse vollkommen legitim. Wenn man die Analyse in den wissenschaftlichen Bereich heben wollte, müsste man hier klare Ziele und Metriken definieren, wieso und ab wann Cluster ähnlich sind. Ab wann sollen sie zusammengefasst werden? Wie genau muss die Karte sein? Sollte man noch klimatische und vegetative Parameter miteinbeziehen?
Letztlich kann man aber auch sagen, unter Beachtung aller möglichen Parameter werden sich wahrscheinlich nur extrem wenige gleiche Gebiete auf der Welt finden lassen. Schottland ist einzigartig, wie jeder Fleck auf der Erde.
Grenzen der Analyse
Das vorliegende Projekt berücksichtigt einzig und allein die Topographie, also die messbare Landschaftshöhe. Es werden sehr viele Dinge ignoriert, die eine Landschaft ausmachen. Das wird besonders klar, wenn man sich verteilte Landschaften anschaut, die in denselben Cluster fallen. Noch mehr wird man das merken, wenn man die Gegenden bereist.
Wenn man jetzt mal die Highlands in Schottland und den Schwarzwald vergleicht, die größtenteils in dieselben Cluster fallen, kann man Folgendes schließen: Schottland zeichnet sich neben der Topografie vor allem dadurch aus, dass hier größtenteils weder Besiedelung noch Wälder existieren. Die Wälder haben es schwer dort, aus anthropogener Behandlung und aus klimatischen Gründen zusammen. Die Bedingungen für die Vegetation und damit auch für die Fauna sind sehr unterschiedlich, vom Wetter ganz abgesehen. Die Gebiete unterscheiden sich auch durch die unterschiedliche Infrastruktur, Erschließung und Zugänglichkeit, Kultur, Industrie, Nähe zum Meer, Bodentypen und vieles mehr.
Es gibt zahlreiche quantifizierbare Unterschiede – und dennoch: Ich würde sagen, als Wanderer – der körperlich die Beschaffenheit der Landschaft erfährt, so wie das diese Analyse nachzustellen sucht – kann man genau nachfühlen, dass die entdeckten Gemeinsamkeiten im Erlebnis der Landschaft doch einen großen Stellenwert haben.
Fazit
Als wichtigste Erkenntnis bleibt mir, dass es für Exploration keine perfekte Lösung gibt. Die entstandenen Karten bieten eine Sichtweise auf die Welt. Ich habe mich sehr viel mit den Landschaften Europas beschäftigt, ganz intuitiv, und habe so mein geografisches Wissen über die Lage bestimmter Regionen zueinander etwas aufgefrischt.
Der größte Nutzen für mich liegt darin, dass ich richtig viel Erfahrung gesammelt und über die Verarbeitung von Geodaten gelernt habe. Ich konnte kreativ ein Bauchgefühl, mein Konzept der topographischen Ähnlichkeit von Landschaften, in Code und sichtbare Ergebnisse umsetzen! Das ist der größte Gewinn.
Die Karten selbst bieten mir eine Auswahl von Landschaften, die ich für eine kommende Reise in Betracht ziehen möchte. Darüber hinaus hoffe ich, dass ich mit diesem Projekt bei Organisationen punkten kann, die Geodaten verarbeiten und nutzen. Sowohl der humanitäre Bereich als auch der Naturschutz sind für mich wünschenswerte Arbeitsfelder.
Ich habe das Projekt so entwickelt, dass die „Stellschrauben“ nachträglich leicht verändert werden können. Man kann also weiter optimieren und das Ergebnis noch weiter verfeinern. Es ist auch leicht, das Projekt auf die ganze Welt auszudehnen – hierfür braucht man aber einiges an Rechenpower – grob überschlagen würde mein Apple M1 Max dafür zwei Tage am Stück arbeiten.
Blick unter die Haube
Ich schreibe rückblickend: Neu für mich war an diesem Projekt die Arbeit mit Geodaten. Zum Beispiel der Zugriff auf die Höhendaten über die API von OpenTopography. Für mich ist die Arbeit mit APIs mittlerweile ganz natürlich geworden.
Dann natürlich die geografische Projektion dieser Daten, also das Umformen der „kugelförmigen“ Höhendaten in „flache“ Kacheln. Es gibt natürlich Libraries, die die Transformationen erledigen, allerdings muss man natürlich vorher genau definieren, was man eigentlich als Ergebnis haben will.
Wichtig war hier, dass die Kacheln messbar gleich große Gebiete abdecken – nicht gleich große Abschnitte in Längen- und Breitengrad. In großen Gebieten wie „Europa“ ergibt sich da eine starke Anisotropie, wenn man in den Höhendaten den Norden mit dem Süden vergleichen will. Ganz einfach gesagt: 1° Länge entspricht in Nordeuropa rund 50 km, im Süden aber rund 90 km, während 1° Breite überall 111,3 km entspricht. Die Kacheln wären also ohne Projektion überall unterschiedlich gestaucht und die Messwerte damit total verfremdet.
Ich arbeitete außerdem mit Dask-Arrays statt NumPy-Arrays. Der Unterschied: NumPy rechnet sofort aus – alle Daten, alle Schritte, sofort im Speicher. Dask plant erst, rechnet aber erst dann, wenn das Ergebnis final berechnet wird. Das senkt den Speicherverbrauch massiv und läuft schneller, weil Dask die Berechnungen intelligenter verteilen kann.